I recently was recently contemplating whether to take my non-phone camera on a trip, and that got me thinking about just how much my photo taking behaviour has changed the last couple years with the rise of really competitive phone cameras. My library of photos dates back to about 2004 and is now about 28k photos large, but it's mostly manageable with the help of Lightroom which I quite enjoy using (performance/subscription issues aside). And luckily for me, Lightroom also has a side benefit of having it's catalogue be a raw SQLite database, which means that we can actually sidestep having to parse RAW files and dealing with EXIF data directly if we want to analyze our photo library.
I couldn't find a good schema for the .lrcat catalogue online, but poking around the database itself suggests that most of the data we want can be resolved from the following few tables:
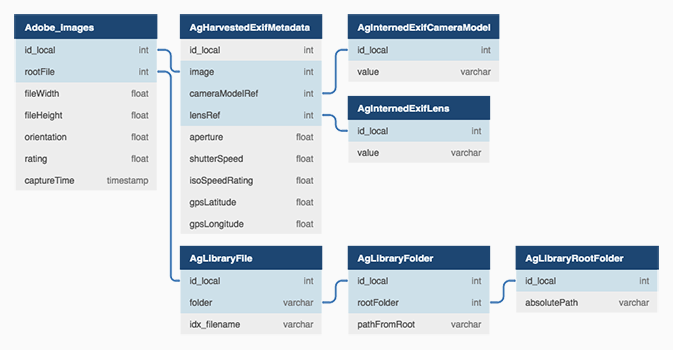
Lightroom catalogue schema (.lrcat)
From there, it's pretty easy to pull the data out into Python to grab some stats with Pandas and Matplotlib.
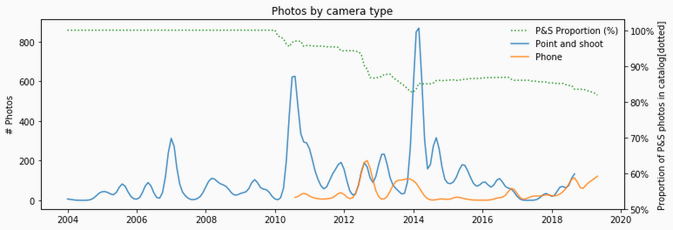
Photos by camera type over time, and proportion of non-phone camera photos in the library
As the chart shows, I didn't really start using phones to take photos until 2010-ish, back when phone camera photos were grainy and blurry in anything but the best lighting situations. But it's pretty clear that the best camera you have is the one you have on you, and nowadays, they are comparable with most point & shoot cameras. The peaks in the non-phone cameras, correspond to either new cameras I got prior to taking trips abroad or other photo-related projects (like an orchid flowering timelapse). Proportionally though, my non-phone photos are now down to 80% of my total library.
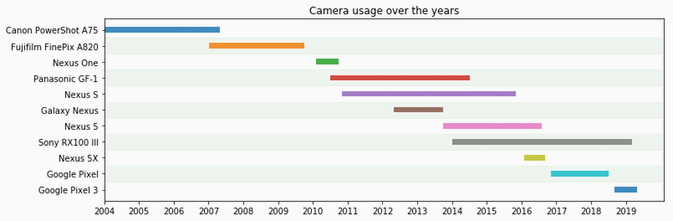
Individual camera usage over time
Looking at each camera usage over time, we can see that on average I end up using most non-phone cameras for about four years, with a number of different phones in between – mainly because I need to upgrade phones for work. As phone camera technology has gotten better, the need to update my non-phone camera has also diminished. At this point, I'm pretty happy with my RX100 and can see myself using it for quite a while longer. What the chart doesn't show though is just how much I shot with each camera.
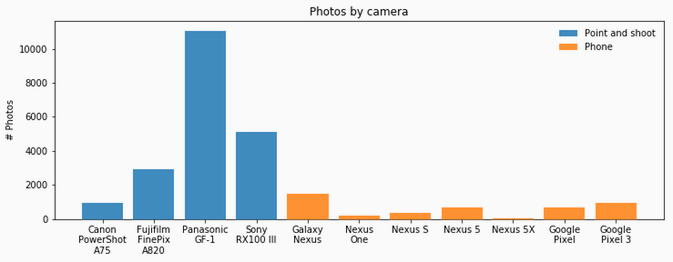
Number of photos taken by each individual camera
Looking at the shots by camera, it's pretty clear that I loved using the GF-1! It's a beautiful camera with intuitive menus in a really convenient form factor (micro four-thirds). I've always really loved the colors that came out as well, and especially liked the 20mm pancake lens. The only downside was the price and speed of the other lenses and that it was only 12MP. Prior to that, I also really liked my A820. I bought it during my first internship in the bay area and I explored a lot of Emeryville/Berkeley/Oakland and SF with it. Maybe because it didn't have too many features to distract you with, I always felt that I spent more time on composition in the pictures from that time. The RX100 I use now is solid – there's perhaps no other word to describe it because it's technically amazing (20MP in a 1 inch sensor), has a fast lens and even faster autofocus. I wouldn't necessarily describe it as a fun a camera to shoot with, but it's very reliable.
As for my phone cameras, I clearly used my Galaxy Nexus a lot (replaceable batteries!), and the Pixel/Pixel 3 are just downright amazing. I've been using Night Sight in some pretty dark environments and they manage to pull out some amazing shots for having such tiny sensors. Phone photos always end up looking like phone photos (a fixed lens, can't really blame it), but with the multi-lens/telescoping phones coming out soon, it'll really only get better.
Megapixel & file size growth over time
It's not all roses though, with each megapixel bump of each camera, the size of each file and the entire library grows. The entire library is about 250gb now with both photos and video. The difference between the solid and dotted lines on the chart reflect (approximately) the compression factor of the files for each camera type. And the 20MP lossy RAWs are quite a bit larger than the comparative JPGs on a per-file basis. Occasionally I try to go through old photos and prune the ones that aren't really interesting to save space, but admittedly it's hard to decide which you want to keep and which you don't – all of them kind of represent some fragment of a memory and it's fun to go back and recall something tiny about a trip that you had totally forgotten!
At the end of the day, I still do like the flexibility of having manual controls and being able to fix exposure issues post-taking the photo, so I'll probably keep bringing my non-phone camera on trips, but it might be just a matter of time before that too changes.

{kind=link}